One of the most frequently used representations of data is a tabular format, wherein, the data is arranged into rows and columns - like we see in spreadsheets. A dataframe is a python object that stores data in rows and columns. The Pandas library can be used to create dataframes and it also has a variety of functions to process, analyze, and visualize data. There are multiple ways in which we can source data into a dataframe.
For example, a dictionary with list as values can be converted to a dataframe such that the keys become headers and values (list) are entries in the dataframe. The orientation of the dataframe by default is columns ie keys are considered as a column header and values are rows. This behaviour can be changed using the orient argument. When orientation is index, an additional argument columns can be used to specify column headers.
The data in a dataframes are arranged in rows and columns both of which have labels. The get a slice of a dataframe, these labels can used with the loc attribute. The columns and index attributes for a dataframe return an iteratable collection of column labels and index labels. To select a subset of a dataframe using indcies for the rows and columns use iloc. Both loc and iloc takes a slice of row label/range and column label/range. Note that a one-dimensional slice of a dataframe returns a Series object i.e. if we select one column or one row, a Series object would be returned. To convert a series object to a dataframe use to_frame function.
Multi-indexing is also possible i.e., a row or a column can have more than one label. In such cases, selections can be made by specifing labels as a tuple.
Pandas offers set of commands to get some basic information about the content of dataframes. Below are some of these command along with their corresponding output.
Column1
Column2
0
A
1
1
B
2
2
C
3
3
D
4
4
E
5
Information about this dataframe
df1.shape (5, 2)
df1.size 10
df1.ndim 2
df1.values [['A' 1]
['B' 2]
['C' 3]
['D' 4]
['E' 5]]
13.3 Data from (and to) a csv file
The read_csv() function can be used to create a dataframe from a csv file. To use one of the columns as indices for the dataframe add the index_col keyword attribute.
Pandas offers a variety of way to combine dataframes. These methods differ in the options in which the data from two or more dataframes can be combined. Having a good understanding of these functions is vital of effectively working with diverse datasets.
Concat
Pandas has a concat function that takes a list of dataframes and returns a combined dataframe. The axis argument indicates whether the dataframes would be combined across rows or columns. The default is axis=0 i.e. the dataframes are concatenated row-wise. The key argument can be used to add an additional index refering to each of the dataframe that is concatenated.
The merge function in pandas is used combine two dataframes on one or more columns. The on argument takes name(s) of column or index levels to be merged. If on is None (default) then all the columns are considred and in case of identical columns, an intersection is performed. When on is specified and the merged dataframe results in duplicate column names then suffixes argument can be used to indicate the original datafames.
The join function for a dataframe oject is used to combine one or more dataframes. By default the joining is performed along the indcies and the lsuffix and rsuffix arguments can be used to modify column names. The on keyword specifies the index label on which to join the dataframes.
To join df4 to df3 on Country, we need to set the index of df4 to Country. Note that in the joined dataframe there is no data for UK since there was no row df3 with UK. This behaviour can be changed by adding the how argument to join function (see below).
Program
PG 75.0
UG 80.0
Name: Marks, dtype: float64
13.6 Styling
The pandas dataframe has a style attribute that return a styler object which has different functions to customize dataframe display. E.g., to highlight minimun and maximum values in a dataframe, the hightlight_min and highlight_max functions for the styler object can be used. The min and max values can be selected column-wise or row-wise by setting the axis argument to 0 or 1, respectively. To highlight min or max value for the entire dataframe use axis = None. The props argument is used to set the highlight properties and takes a valid CSS (Cascading Style Sheet) property.
df_1 = pd.DataFrame(np.random.uniform(1,2,size=(5, 4)), columns=list('ABCD'))display(df_1.style.highlight_max()\ .set_caption("Column-wise highlighting of maximum value"))display(df_1.style.highlight_min(axis=1,props="font-weight:bold;background-color:pink;")\ .set_caption("Row-wise highlighting of minimum value"))
Column-wise highlighting of maximum value
A
B
C
D
0
1.171781
1.734401
1.907562
1.664692
1
1.045334
1.306548
1.608249
1.983291
2
1.599308
1.803451
1.180637
1.827385
3
1.842809
1.127118
1.010549
1.193096
4
1.844464
1.018964
1.629553
1.459751
Row-wise highlighting of minimum value
A
B
C
D
0
1.171781
1.734401
1.907562
1.664692
1
1.045334
1.306548
1.608249
1.983291
2
1.599308
1.803451
1.180637
1.827385
3
1.842809
1.127118
1.010549
1.193096
4
1.844464
1.018964
1.629553
1.459751
We can also highlight all the values in a dataframe with color gradient. The coloring can be applied to the text or background. The cmap argument for background_gradient and text_gradient functions can be used to customize the coloring based on a colormap.
The values in a dataframe can be decorated with bar plots using the bar function for the styler object. In this example, we’ll display the dataframe after applying the following customizations:
- bar plots with custom color map.
- format the floats to display upto two decimal places.
- make the text bold.
- center align the text in the dataframe.
- hide the indcies.
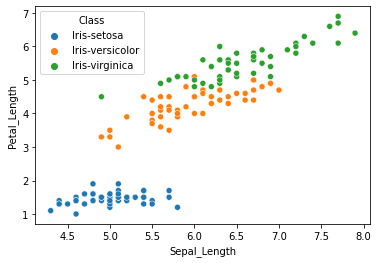
One of the popular datasets for learning data analysis is the iris dataset which has data for four iris flower features (sepal length, sepal width, petal length, and petal width). These data are there for the three species namely Iris setosa, Iris versicolour, and Iris virginica. Let’s import this data create a dataframe and practice data visualization.
csv_url ='https://archive.ics.uci.edu/ml/machine-learning-databases/iris/iris.data'# using the attribute information as the column namescol_names = ['Sepal_Length','Sepal_Width','Petal_Length','Petal_Width','Class']iris = pd.read_csv(csv_url, names = col_names)
To get the summary statistics for this dataset we’ll use the describe function for the iris dataframe. This function calculates different statistical parameters for all the columns with numeric data. Notice that this summary would be for the entire data and so might not be of much use. A better approach would be first aggreate the data by species so that we can get summary statistics for each species.
The Seaborn library is data visualization library based on Matplotlib. This library is particularly suitable for ploting with dataframes. The libaray has been specifically designed and develop in way to focus on the data analysis rather than worrying about nuances of drawing plot.
import matplotlib.pyplot as pltimport seaborn as sns
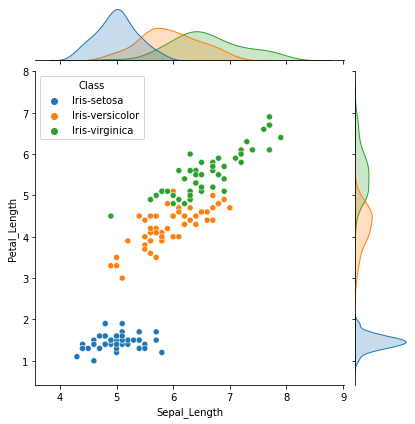
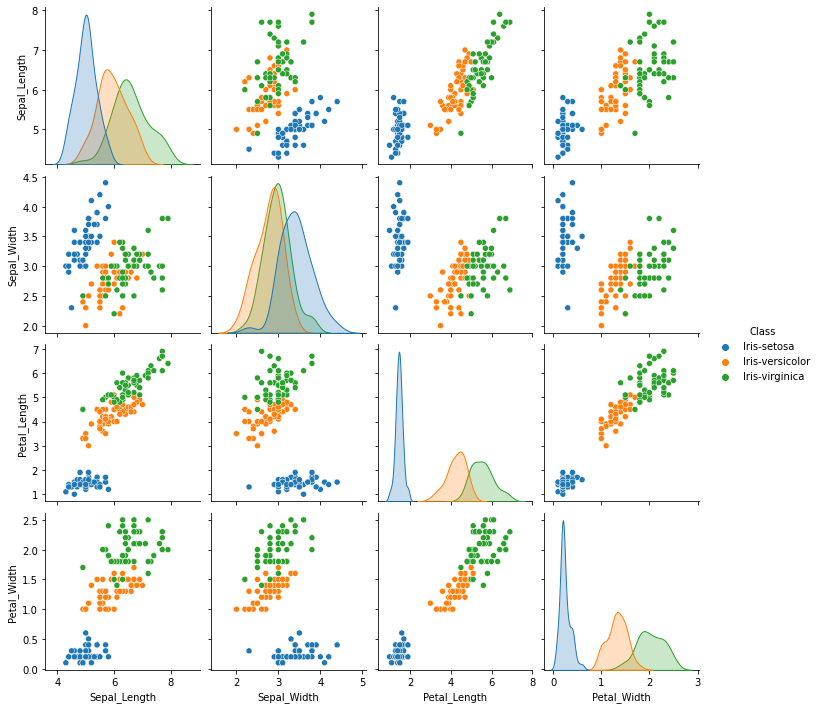
The seaborn library has dedicated functions to facilitate ploting informative visualizations. E.g., jointplot is used for rendering a scatter plot along with the corresponding data distributions. Similarly, pairplot can be used to render pairwise plots for all the numeric data in a dataframe.
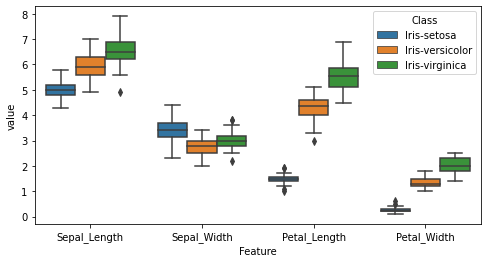
We can also visualize statistical information graphically, e.g. in the form of a boxplot. For this kind of a plot, we first need to edit our dataframe so that its in the required format. Using the melt function in pandas, the original iris dataframe would be modified such that the values for all four flower features appear one per row. This would allow us to perform statistical calculations (required for boxplot) on all the feature and color the plot based on the species. Notice that the original iris dataframe’s shape is 150 X 5 (which implies a total of 600 datapoints since there are 4 data columns) while the melted dataframe’s shape is 600 X 3.